
Automation 360を使用したロボット開発でPDFからのデータ取得をする際には、まず「PDF」パッケージを使用することが一番最初に想定されますが、このパッケージはテキスト形式PDFにしか抽出できないパッケージで、画像形式PDFの場合だと「PDF」パッケージではテキストを抽出することが出来ません。
その代わり画像形式PDFから文字を抽出する場合は「OCR」パッケージを使用した、画像の文字を読み取ることに特化したパッケージを使用しなくてはいけません。
今回のコンテンツではAutomation 360の開発でPDFの処理設定をより詳しく知りたい、他のパッケージでPDFのデータ抽出のTipsを知りたいという人に今回はPDFの構成ごとの処理設定方法についてご紹介させていただきます。
目次
PDFの種類の違いと使い分け方
PDFにはテキスト形式PDFと画像形式PDFの2つがあります。
テキスト形式PDFと画像形式PDFとは
テキスト形式PDF
Wordファイルやテキストファイルのようなテキスト情報を埋め込んだPDFになります。
こちらはPDF内にある文章を検索することができたり、コピーして他の文章貼り付けたりすることも可能で、PDFの文字編集することが可能です。
画像形式PDF
テキスト形式PDFとは違い、画像を中心に作成されたPDFのことで、スキャンされた画像や図形と言った情報で作成されています。
テキストデータで作成されているわけではないので、文章の検索やコピーを行うことが出来ませんが、文章のフォント等が無いので見た目を正確に維持することが出来ます。
テキスト形式=「PDF」パッケージ、画像形式=「OCR」パッケージがおススメ
この項目ではテキスト形式=「PDF」パッケージで画像形式=「OCR」パッケージがオススメしているのかに対して詳しく紹介します。
「PDF」パッケージは主にテキスト形式に対しての処理するためのアクションが多く、画像形式PDFで「PDF」パッケージのアクションを使用しても文字を抽出することはできません。
そのためテキスト形式PDFでは「PDF」パッケージをおすすめしております。
また「OCR」パッケージに関して、画像や紙の文章を読み取ってテキストデータを抽出する機能ですので、画像形式PDFとの相性がとても良いです。
次の章ではそのパッケージに対しての処理設定についてご説明いたします。
Automation 360でテキスト形式と画像形式のPDFを操作するパッケージ
テキスト形式PDFと画像認識PDFではデータ抽出するために使用するパッケージが変わります。
PDFの形式に対して使用するAutomation 360のパッケージが変わります。
この章ではその2つのPDFに対してのデータを抽出する際にどのパッケージを使うべきかご紹介いたします。
テキスト形式PDFを操作するパッケージ
Word、Excelなどドキュメントから変換された文字列タイプの編集可能なPDFファイルに対してはPDFのパッケージを使用するのをオススメします。
理由として、このPDFパッケージはテーブルやリストなどの構造化されたデータからでもテキストを抽出することができて文字認識技術の制度が高いためです。
またテキスト形式のPDFからデータを抽出する際に使用するアクションをご紹介いたします。
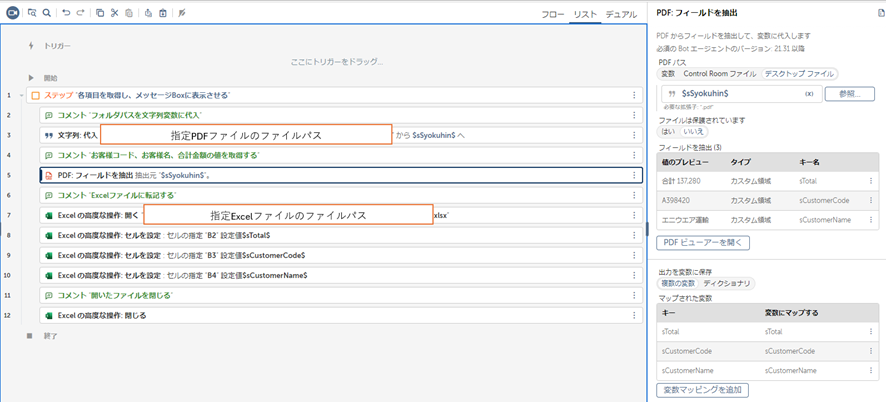
よく使うアクション紹介:PDF:フィールドを抽出
「PDFビューアー」から指定したPDFを開いて取得したいデータを描画してテキストデータを抽出する操作がございます。
こちらは必要なデータだけテキストを抽出して変数に格納することができますので、PDFの一部の情報しか必要ないという時に使用します。
以下に設定方法をご説明いたします。
【設定方法】
- 指定のPDFファイルのパスを設定
- 「PDFビューアーを開く」から指定のPDFファイルのパスを入力し、PDFファイルを開く
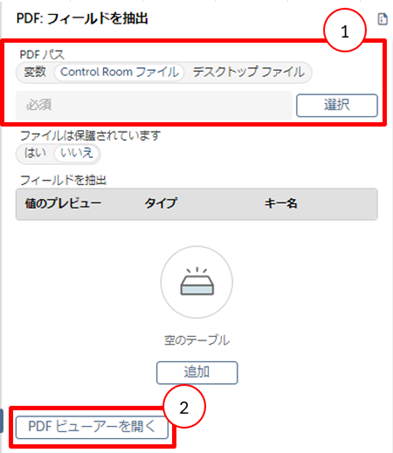
- 左上から「領域を描画」から今回出力したい箇所をクリックし、ドラッグして領域を作成後にキーを作成。

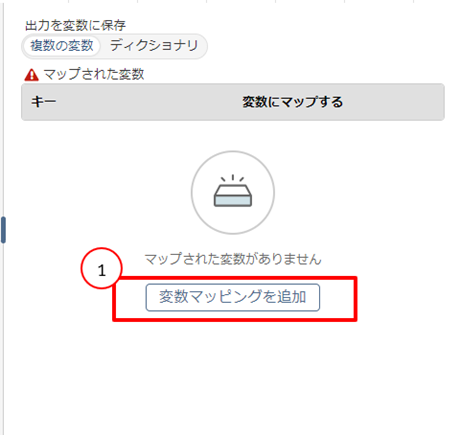
- 「変数マッピングを追加」で作成したキーを変数で格納しデータ抽出
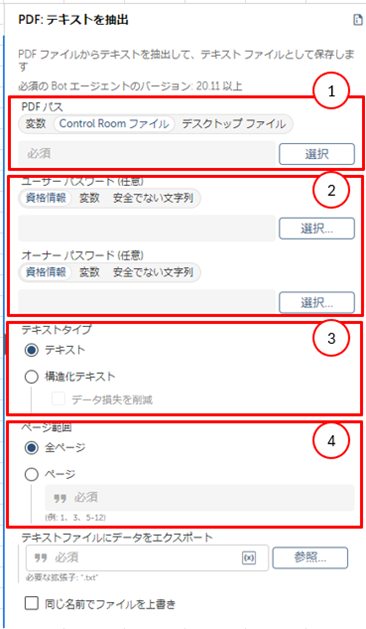
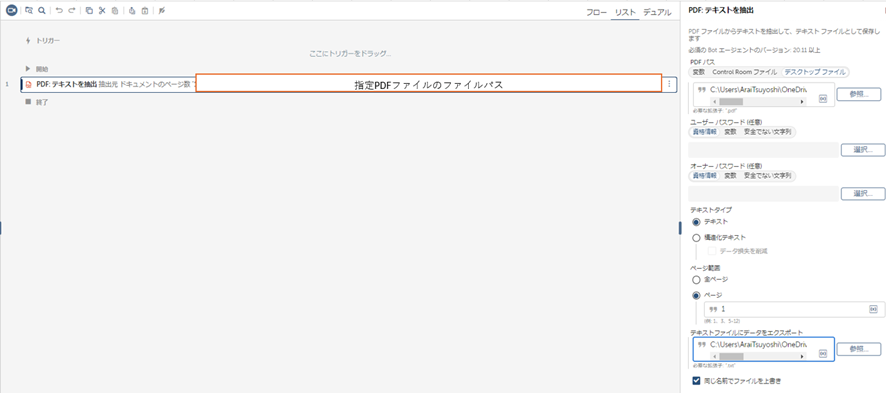
よく使うアクション紹介:PDF:テキストを抽出
指定したPDFが複数ページある場合に使用するアクションになります。
このアクションの特徴として全ページのテキストを取得するか、特定のページだけテキストを抽出するかを選択することが可能です。
こちらは取得した値を変数に格納することが出来るかつテキストファイルに値を出力することができます。
以下に設定方法をご説明いたします。
【設定方法】
- 指定のPDFファイルのパスを設定
- 指定のPDFがアクセス制限で暗号化されている場合は開く際のパスワードを設定
- データ抽出方法を設定
- テキスト
PDFファイルからテキストをコピーして出力したテキストファイルにそのまま貼り付けることができます。(コピー&ペーストのような操作) - 構造化テキスト
PDF ファイルから抽出されたテキストの元のフォーマットを保持することができます。
さらに「データ損失の軽減」を選択すると文字の重複を最小限に抑えてテキストを抽出することができます。
- テキスト
- 出力したいページ範囲を設定
画像形式PDFを操作するパッケージ
文字列タイプではなく、画像ファイルから変換されたPDFの場合は構造上文字列が存在しないため、PDFのパッケージでテキストデータを抽出することが出来ません。
その代わりOCRパッケージをという画像に記載されている文字を認識させることでテキストデータを抽出することが出来ます。
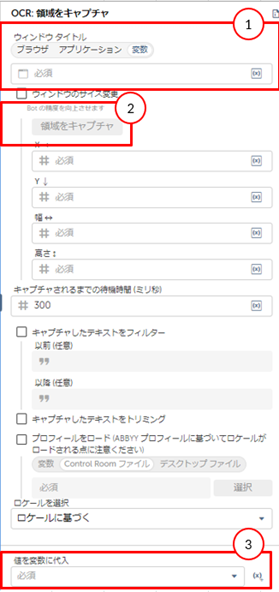
よく使うアクション紹介:OCR:領域をキャプチャ
画像形式のPDFからテキストデータを取得する場合は「領域をキャプチャ」というアクションを使用します。
【設定方法】
- 今回使用するPDFファイルを事前に開く
- ウィンドウタイトルで対象PDFのウィンドウ名を選択
- 領域キャプチャをクリックし、出力したい箇所を範囲選択して右クリックをすると領域が作成される
- テキストを格納するための変数を作成する
Automation 360ではPDFタイプに合わせて使用するパッケージを使い分けることによってテキストデータを取得することができます。
ここまでで2つのPDFタイプの使い分け方法や設定方法についてご紹介させていただきました。
次の章では2つのPDFタイプごとの事例をいくつかご紹介させていただきます。
Automation 360で各種PDFを自動化する事例
各種PDFに合わせた自動化事例を2つご紹介
ここでは先程ご紹介したパッケージの内容を形式ごとにご紹介いたします。
テキスト形式PDFの自動化事例
フィールドを抽出アクションを使用した事例
【事例内容】
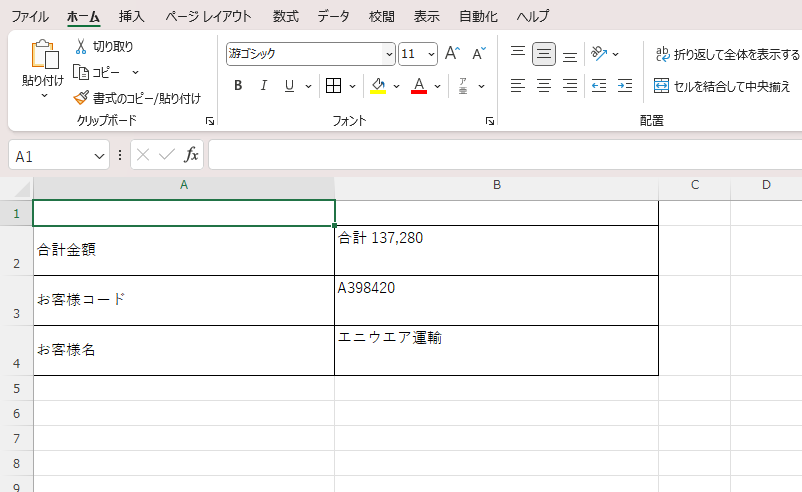
指定のPDFファイルからお客様コード、お客様名、合計金額のテキストデータを抽出し、Excelファイルに転記する。
【設定方法】
- 「フィールドを抽出」のアクションを使用し、対象PDFのフォルダパスを入力
- 「PDFビューアーを開く」で指定したPDFから特定のテキストデータを抽出し、各キーを設定
- ②で設定したキーを「変数マッピング」で変数に格納
- 「Excelの高度な操作:開く」で特定のExcelのパスを指定して開く
- ②で格納した変数をExcelの決まったセルに転記していく
- Excelファイルを閉じる
<事例の出力結果>
テキストを抽出アクションを使用した事例
【事例内容】
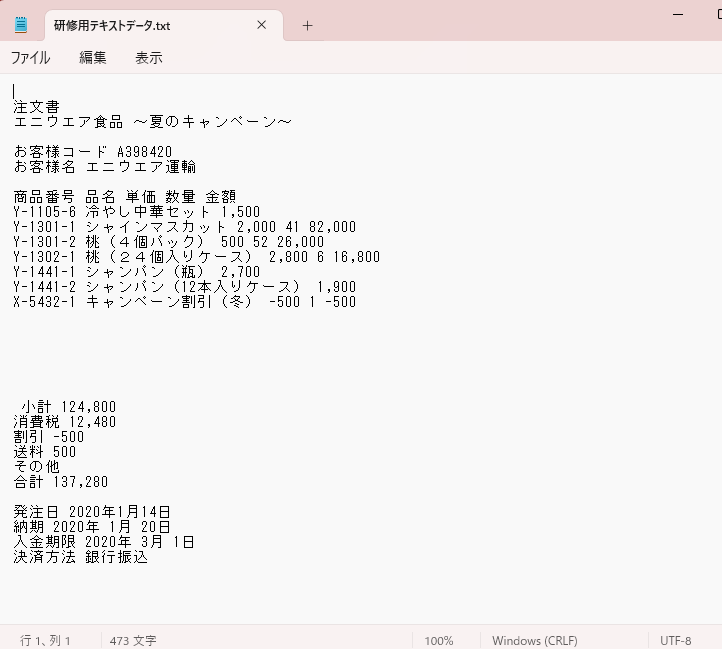
指定の複数ページあるPDFファイルから最初の1ページ目のテキストを抽出し、テキストファイルに保存
【設定方法】
- 「テキストを抽出」のアクションを使用し、対象PDFのフォルダパスを入力
- テキストタイプで「テキスト」を選択
- ページ範囲で「ページ」を選択し、抽出するページを入力
- 抽出したページを今回保存するテキストファイルに選択
※上書き保存ができるように、「同じ名前でファイルを上書き」にチェックを入れる。
<事例の出力結果>
画像形式PDFの自動化事例
【事例内容】
指定のPDFファイルから請求日、会社名、支払期限をテキストデータに抽出し、指定のExcelファイルに転記する
【設定方法】
- 「アプリケーション:プログラム/ファイルを開く」で特定のPDFのパスを指定して開く
- OCRの「領域をキャプチャ」で取得したいテキストデータを範囲選択して変数に格納する
- 「Excelの高度な操作:開く」で特定のExcelのパスを指定して開く
- ②で格納した変数をExcelの決まったセルに転記していく
- Excelファイルを閉じる
- PDFファイルを閉じる
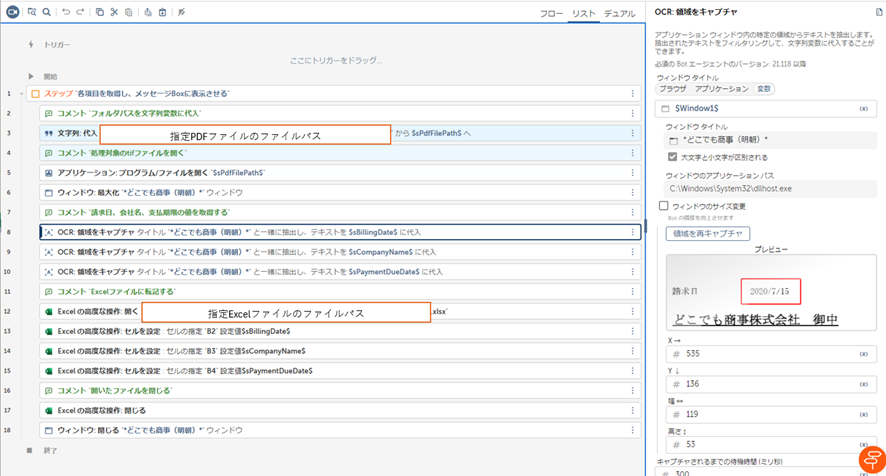
<事例の出力結果>
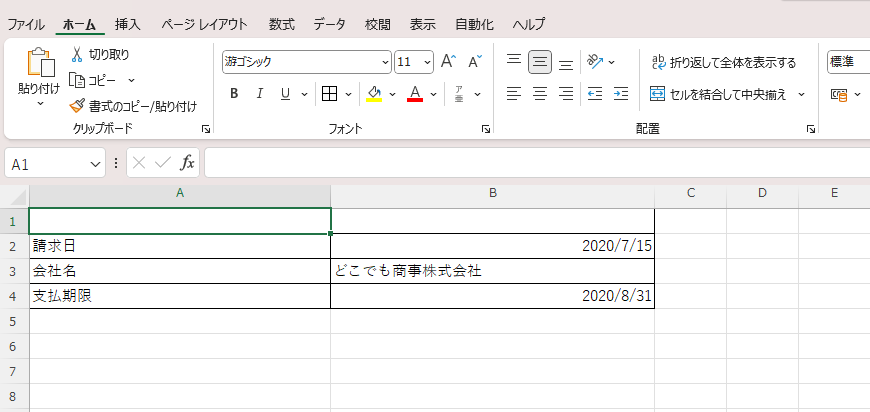
このように使用するパッケージによって、同じテキストを抽出する動作であってもRPAでの設定が異なります。
そのためAutomation 360で設定する際に対象PDFはどのタイプなのか確認をする必要があります。ここまででPDFの設定方法と事例をご紹介させていただきましたが、次の章ではRPAでPDFファイルを自動化する際の注意事項についてご説明させていただきます。
RPAによるPDF自動化の注意事項
必ずしも100%の精度で取得できるわけではない
RPAではテキストタイプでも画像タイプでも必ずしも100%の精度で値を取得できるわけではありません。
枠が狭かったり、文字の間隔が狭いと、文字がつぶれてしまい他の文字として取得してしまう場合があります。
また画像の場合は解像度によっても精度が左右されてしまいます。
画像が粗い場合は特に取得したい文字とは別の値が取れてしまう可能性があるので、可能な限り解像度を上げる、RPA設定時には余裕をもった枠で設定するなどの工夫が必要です。
読取精度に関しては取り込むドキュメントに左右される部分が大きいため、取り込んだ後に目視でのチェックプロセスを入れる、Pythonスクリプトを使用し読替ルールを設定するなど、その後の業務プロセスで求められる要件に応じて、プロセスを設計することも重要です。
今回はAutomation 360でのPDFの設定方法をご紹介させていただきました。
弊社ではAutomation Anywhere以外にもUiPathやBizRobo!などのツールを使用して様々な支援をさせていただいております。
RPAツールを導入したけど、実際にどう開発したらいいのかわからない、そもそも対象業務が自動化に向いているのかわからないという方は是非弊社までお問合せ下さい。
内容をヒアリングした上で、開発方法や自動化の可能性をご提案させていただきます。








ペネトレイター株式会社 荒井